Лекция 7
Распространенные практики в многопоточности
Содержание
- пул потоков (thread pool);
- асинхронное программирование;
- атомарные операции и lock-free.
Пул потоков
Переключение контекста
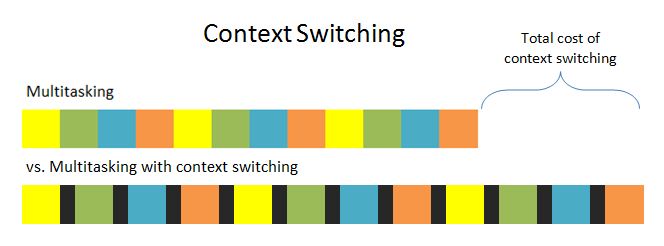
Переключение контекста
Большое количество потоков требует больших вычислительных ресурсов на их планирование и выполнение.
Чем больше потоков, тем больше переключений и тем больше памяти требуется для хранения контекстов.
Переключение контекста
Зачастую бывает полезно ограничить количество потоков в приложении, чтобы снизить накладные расходы и достичь наибольшей выгоды от многопоточности.
Очередь перед кассой

Пул потоков
Проблему огромного количества потоков в приложении призван решить пул потоков.
Пул потоков
В стандартной библиотеке C++ нет пула потоков.
Но его несложно реализовать с помощью стандартных средств C++ для своих целей.
Пример ThreadPool
1 #include <type_traits>
2 #include <future>
3
4 class ThreadPool {
5 public:
6 ThreadPool(size_t workers_count);
7
8 template<class F,
9 class... Args,
10 class R=std::result_of_t<F()>>
11 std::future<R> enqueue(F&& func, Args&&... args);
12 };
Пример ThreadPool
Основной метод любого пула потоков – это метод, с помощью которого можно добавлять задачу на выполение.
В примере выше, это метод enqueue.
Метод enqueue
std::future<R> enqueue(F&& func, Args&&... args);
- метод возвращает
futureна результат выполнения функции - принимает функцию
func, которую необходимо выполнить - и принимает аргументы
args, которые необходимо передать в функциюfuncво время выполнения
Метод enqueue
Аргументы повторяют аргументы функции std::async (за исключением первого параметра std::launch policy).
По факту, std::async может не создавать новый поток для исполнения задачи, а использовать поток из встроенного пула, но это зависит от конкретной реализации компилятора.
Пример
1 // Создаем пул потоков на 10 потоков.
2 static ThreadPool pool(10);
3
4 Response GetRequest(std::string uri);
5
6 void HttpHandler(Request req);
7 // Добавляем задачу на выполение в пул потоков.
8 pool.enqueue(HttpHandler, std::move(req));
9 // Добавляем задачу на выполение в пул потоков.
10 std::future<Response> response =
11 pool.enqueue(GetRequest, "http://cppreference.com/");
12 // Working...
13 // Получение результата функции GetRequest.
14 std::cout << response.get();
Как устроен пул потоков
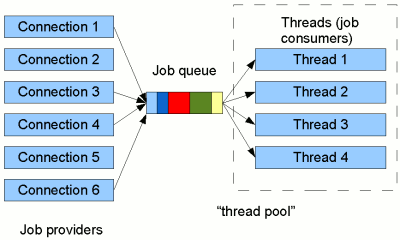
Как устроен пул потоков
По сути, это применение шаблона producer-consumer.
В качестве consumer’ов выступают потоки, которые выполняют поставленные в очередь задачи.
В качестве producer’ов – пользовательский код.
Модификации пула потоков
Иногда, чтобы решить задачу в “виртуальном” мире достаточно посмотреть как подобная задача решается в “реальном” мире.
Динамическое добавление и снятие потоков
В магазине не на всех кассах сидят кассиры. Но в случае большой загруженности магазина на свободные кассы приходят работники.
В случае отсутствия покупателей кассиры могут выполнять другую работу, либо берут отгулы, что экономит магазину ресурсы.
Локальные очереди для каждого потока
У каждой кассы собираются небольшие очереди. Это помогает очередям двигаться быстрее, а не толкаться в большой очереди мешая друг другу добираться до свободных кассиров.
Но иногда у одной кассы собирается большая очередь, а другие пустуют.
Резюме
- пул потоков предоставляет высокоуровневую абстракцию, позволяющую не задумываться о ручном управлении потоками
- пул потоков позволяет избежать накладных расходов на создание и уничтожение нового потока
- пул потоков помогает уменьшить суммарное время, затрачиваемое на переключение контекста потоков
Асинхронное программирование
Как приготовить ужин

Как приготовить ужин

Cинхронная модель
Обычно в программировании используется последовательное синхронное выполнение инструкций и вызовов функций, которые блокируют поток выполнения.
Пример
1 void Echo(tcp::socket socket) {
2 std::array<char, 1024> data;
3 while (true) {
4 // |read_some| - синхронная функция.
5 // Поток остановится до завершения |read_some|.
6 std::size_t n = socket.read_some(
7 boost::asio::buffer(data));
8
9 // |write_some| - синхронная функция.
10 // Поток остановится до завершения |write_some|.
11 socket.write_some(
12 boost::asio::buffer(data, n));
13 }
14 }
15 while (true) {
16 tcp::socket socket = acceptor.accept();
17 std::thread(Echo, std::move(socket)).detach();
18 }
Cинхронная модель
Одна из проблем такого подхода в том, что часто приходится ждать неких внешних событий: чтение файла с диска, передача/получение данных по сети и т.д.
Cинхронная модель
При этом текущий поток вынужден ждать, а не выполнять полезную работу.
Это приводит к проблемам производительности приложения.
Асинхронная модель
В асинхронной модели программирования поток может приостановить выполнение задачи, сохранив текущее состояние, и начать выполнение другой задачи.
Асинхронная модель
Системные вызовы выполняются в неблокирующем режиме, что позволяет потоку продолжить работу.
Пример
1 void Echo(tcp::socket socket) {
2 std::array<char, 1024> data;
3 auto on_write_callback =
4 [=](boost::system::error_code ec, size_t n) {
5 Echo(std::move(socket));
6 };
7 auto on_read_callback =
8 [=](boost::system::error_code ec, size_t n) {
9 socket.async_write_some(
10 boost::asio::buffer(data, n), on_write_callback);
11 };
12 socket.async_receive(
13 boost::asio::buffer(data), on_read_callback);
14 }
15 void DoAccept() {
16 tcp::socket socket;
17 auto callback = [socket](boost::system::error_code ec) {
18 Echo(std::move(socket));
19 DoAccept();
20 };
21 acceptor.async_accept(socket, callback);
22 }
Замечание
Представленный выше код является псевдокодом. Реальный код не представлен на слайдах для упрощения понимания примера.
Чтобы увидеть работающий код, смотрите пример к лекции.
Псюсы асинхронности
Использование асинхронного программирования позволяет одному потоку обрабатывать несколько задач, а не простаивать, пока выполняется системный вызов.
Функции обратного вызова
Функции обратного вызова (callback) – функции, которые будут вызываны после того, как завершится задача, запущенная в асинхронном режиме.
Callback
С помощью callback’ов можно обрабатывать результат асинхронных операций.
Callback
1 socket.async_receive(boost::asio::buffer(data), on_read_callback);
В примере лямбда on_read_callback является callback-функцией.
Лямбда on_read_callback будет вызвана после того как будут получены данные по сети и завершится системный вызов.
Проблемы callback-функций
Код с использованием callback-функций становится запутанным, нарушается последовательность кода.
Легко “заблудиться”, в какой момент и в каком порядке будут вызываться callback-функции.
Проблемы callback-функций
Всегда необходимо заботиться о времени жизни объектов, которые используются в callback-функциях.
Совет
Всегда, когда имеете дело с callback-функциями, думайте о времени жизни объектов, с которыми работаете в callback’ах.
Сопрограммы
Чтобы решить проблемы, связанные с использованием callback-функций, можно воспользоваться сопрограммами (coroutine).
Сопрограммы
Сопрограмми называются функции, имеющие несколько точек входа, в то время как, у обычных функций есть только одна.
Пример
1 awaitable<void> Echo(tcp::socket socket) { // <- Entry point 1.
2 std::array<char, 1024> data;
3 while (true) {
4 std::size_t n = co_await socket.async_read_some(
5 boost::asio::buffer(data), use_awaitable);
6 // <- Entry point 2.
7 co_await async_write(
8 socket, boost::asio::buffer(data, n), use_awaitable);
9 // <- Entry point 3.
10 // some code...
11 }
12 }
1 while (true) {
2 tcp::socket socket = co_await acceptor.async_accept(
3 use_awaitable);
4 Echo(std::move(socket));
5 }
Точки входа
Функция Echo является сопрограммой. У нее три точки входа:
- Как у обычных функций в начале тела функции;
- После асинхронного чтения данных из сокета;
- После асинхронной записи данных в сокет.
co_await
Оператор co_await приостанавливает сопрограмму и возвращает управление вызывающему коду.
co_await
После того как завершится операция, запущенная в асинхронной функции, сопрограмма продолжит свою работу с того места, где была приостановлена, т.е. со своей следующей точки входа.
Преимущества сопрограмм
Использование сопрограмм позволяет писать асинхронный код, который выглядит как синхронный. Такой код проще реализовывать, отлаживать и использовать.
Резюме
-
асинхронное программирование позволяет избежать появления узких мест производительности и увеличить общую скорость реагирования приложения
-
асинхронность необходимо использовать при наличии потенциально блокирующих работу действий
-
асинхронность полезна при обращении к потоку пользовательского интерфейса
Резюме
- при разработке callback-функций продумывайте, как объекты “доживут” до вызова callback’a
Резюме
-
использование сопрограмм в асинхронном программировании помогает упростить код
-
в зависимости от реализации сопрограммы иногда бывают эффективнее callback’ов
-
сопрограммы полезны не только при асинхронности, например, еще и при реализации генераторов
Атомарные операции
Атомарные vs неатомарные
Операция называется атомарной, если она выполняется как единое целое, либо не выполняется вовсе. Т.е. она не может быть частично выполнена или частично не выполнена.
Если один поток выполняет атомарную операцию, то другие потоки не могут “вмешаться” в выполнение этой операции (например, получить её промежуточное значение).
Атомарные vs неатомарные
Неатомарные операции такой гарантией не обладают.
Неатомарная переменная
1 int global_count = 0;
2 std::vector<std::thread> group;
3
4 void inc() {
5 ++global_count;
6 }
7
8 for (int i = 0; i < N; ++i) {
9 group.push_back(std::thread(inc));
10 }
11 for (auto& th : group) {
12 th.join();
13 }
14 // global_count == ?
15 std::cout << global_count;
Атомарная переменная
1 std::atomic<int> global_count = 0;
2 std::vector<std::thread> group;
3
4 void inc() {
5 ++global_count;
6 }
7
8 for (int i = 0; i < N; ++i) {
9 group.push_back(std::thread(inc));
10 }
11 for (auto& th : group) {
12 th.join();
13 }
14 // global_count == N
15 std::cout << global_count;
atomic
load()- получить текущее значениеstore()- присвоить новое значениеis_lock_free()- возвращает true, если операции на данном типе неблокирующиеoperator++- инкрементexchange()- установить новое значение и вернуть предыдущееcompare_exchange_strong()- аналог CAScompare_exchange_weak()- аналог CAS- …
CAS (Compare and Swap)
Операция атомарно сравнивает значение одного объекта с другим и при равенстве измениет значение объекта.
compare_exchange
1 // Псевдокод. Вся функция работает атомарно.
2 bool compare_exchange(T& obj, T& expected, T value) {
3 bool result = (obj == expected);
4 if (result) {
5
6 obj = value;
7
8 } else {
9
10 expected = obj;
11
12 }
13 return result;
14 }
compare_exchange
Разница между compare_exchange_weak и compare_exchange_strong заключается в том, что compare_exchange_weak на некоторых платформах может вернуть false и НЕ выполнить обмен даже в случае равных значений.
Lock-free программирование
Неблокирующая синхронизация – подход в параллельном программировании, в котором принят отказ от традиционных примитивов блокировки.
Недостатки блокировок
- блокировки - довольно медленные операции
- при блокировках поток с низким приоритетом может заблокировать поток, с более высоким приоритетом
Определение
-
Процедура считается lock-free, если для нее гарантируется прогресс как минимум одного потока, выполняющего эту процедуру. Другие потоки могут ждать, но минимум один поток должен прогрессировать.
-
Операция называется wait-free, если она завершается за определенное количество шагов, не зависящих от состояние и действий других потоков.
Реализация lock-free
Неблокирующие алгоритмы строятся на атомарных операциях.
Одна из самых значимых операций при lock-free программировании – это сравнение с обменом (CAS).
Lock-free stack
Чтобы лучше разобраться с lock-free алгоритмами, необходимо рассмотреть пример.
Для этого реализуем потокобезопасной стек с использованием lock-free программирования.
LockFreeStack
1 template <typename T>
2 struct LockFreeStack {
4 void Push(const T& value);
5 Node* Pop();
6
7 struct Node {
8 T data;
9 Node* next;
10 };
11 private:
12 std::atomic<Node*> head_;
13 };
Push
1 void Push(const T& value) {
2 Node* new_head = new Node(value, head_.load());
3
4 while (
5
6 !head_.compare_exchange_weak(new_head->next, new_head)
7
8 ) { }
9 }
Pop
1 Node* Pop() {
2 Node* node = head_.load();
3
4 while (node &&
5
6 !head_.compare_exchange_weak(node, node->next)
7
8 ) { }
9
10 return node;
11 }
Резюме
- lock-free программирование – один из альтернативных методов реализации потокобезопасного кода
- lock-free программирование – не панацея и не надо бездумно применять его вместо блокирующих операций
- lock-free программирование – может, но не обязано, повысить производительность вашего приложения
Домашнее задание
- C++20. Coroutines https://m.habr.com/ru/post/519464/
- stackfull coroutines vs stackless coroutines
- освобождение памяти в lock-free структурах данных